

エクサウィザーズは、画像の内容を基にその状況を対話型で説明する生成AIモデル「exaBase Visual QA」を開発したことを発表した。この新しいモデルは、一般的な生成AIモデルと比較して、画像内の危険性や状況を高精度に解釈し、説明文を生成する能力を持つ。
エクサウィザーズは、AIの活用を通じて、サービスやプロダクトの提供を行い、生産性の向上や社会課題の解決を目指している。今回の「exaBase Visual QA」は、特に複雑な画像の危険性や内容を的確に文字情報として出力するのが難しいとされる問題に対応するためのものだ。
このモデルは、人が画像を見た際にどこに注目するのかを学習し、その結果、人が直感的に認識可能な画像内の状況を高精度で解釈することができるようになった。例えば、特定の画像に「潜在的な危険性はありますか」との質問を投げかけると、「作業員がバランスを崩したり足場が崩れたりすると落下につながる。作業員は金属棒を接続するために電動工具を使用しており、工具が滑ると負傷する可能性がある。適切な安全予防措置を講じるべきである」といった説明文を生成する。
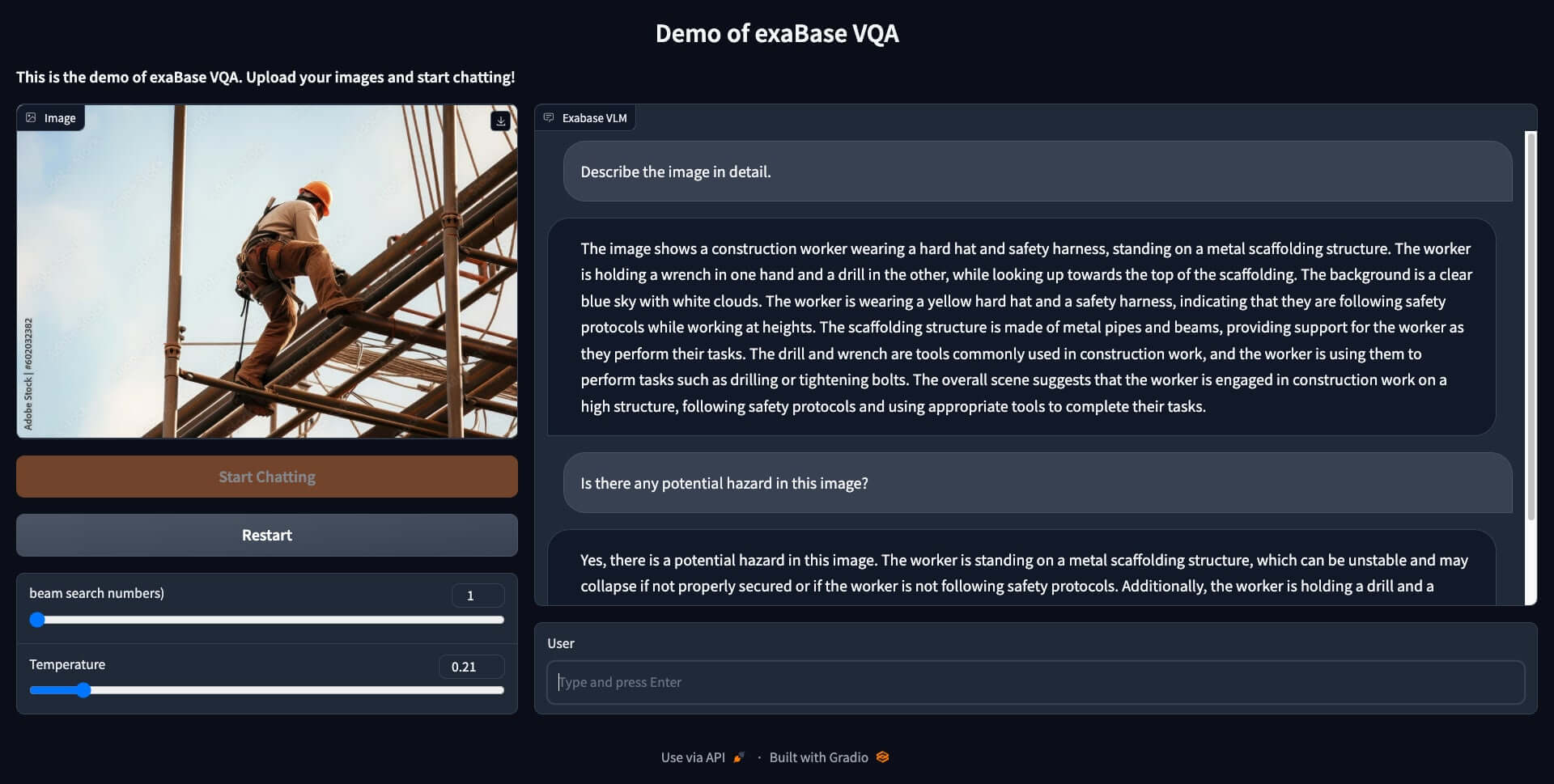
さらに、エクサウィザーズの評価実験によれば、このモデルは他の商用利用可能なモデルよりも最大で1割弱高い解釈の精度を持っていることが確認されている。また、モデルのサイズが小さく、推論や生成の速度も高速である。
「exaBase Visual QA」は、オープンソースの生成AIモデルを基に開発され、エクサウィザーズが追加学習を行っているため、すぐに利用が可能である。特定の分野のデータを学習し、設定を調節する「ファインチューニング」も提供されており、特定の分野での精度をさらに向上させることが期待される。
このモデルは、建設現場や保育園、学校などの様々な場面での状況把握や、故障場所の把握、事件や事故の把握など、幅広い分野での利用が想定されている。今後の展開としては、静止画だけでなく、動画での活用も視野に入れている。
【関連リンク】
インタビュー・取材記事掲載はこちら


